Disclaimer: I wrote this article on March 2022 while working with Subspace, and the original link is here: https://subspace.com/resources/ice-negotiation . This post in my personal blog is a way to ensure it doesn't get lost. There is nothing service-specific in it, I've made only minor edits and I hope it can be a good technical reference on the topic.
WebRTC is a set of protocols that allow applications, typically running on Web browsers, to exchange media (audio, video, data) with other entities.
Before media can flow, however, the WebRTC entities need to discover what type of connection is possible, and among the possible connections, what’s the best to be used. This needs to happen as fast as possible, so that users can perceive the service as instantaneous as possible.
WebRTC includes protocols like STUN and TURN that are designed to facilitate the establishment of connections when a direct connection is not possible. The typical case is a computer inside a home or office network, with a private IP address, and able to reach the public Internet only through an address translation (NAT).
STUN helps in discovering the IP address and port from where a computer enters the Internet, and in some circumstances that IP address and port can be used by other entities to reach that computer. STUN is also used for keeping such bindings alive.
TURN provides a way for two entities to communicate when they are behind two different symmetric NATs, or when one is behind a firewall that restricts outbound traffic to only some UDP or TCP ports. TURN uses STUN as the underlying protocol, adding requests, responses and indications to accomplish media relay.
STUN and TURN play a role in the ICE negotiation process. ICE, Interactive Connectivity Establishment, is a protocol that allows the dynamic discovery of the best way to establish a connection for entities that may be behind NAT.
All WebRTC clients use ICE before media can flow.
There are three main phases: the gathering of candidates, the connectivity checks, and the nomination of the candidate pairs to be used.
The ICE candidates are simply transport addresses (IP address, port and transport type) that can potentially be used to communicate (send and receive media) and that the ICE client collects and shares to the other party through some form of signalling.
There are three main types of ICE candidates: 'host', 'server reflexive' and 'relay'.
'host' candidates refer to transport addresses that are directly visible by the client, where the client can start listening for incoming connections or packets. Computers behind NAT may only have private IP addresses as 'host' candidates, but they are potentially usable if the other party belongs to the same network, or depending on the type of NAT.
'server reflexive' candidates are the ones discovered through the interaction with a STUN server. The client sends a Binding Request to the STUN server and receives a Binding Success Response with a MAPPED-ADDRESS containing the source IP address and port from where the request was received. There may be more than one level of NAT, and that transport address represents the outmost one.
'relay' candidates refer to allocations reserved on a TURN server. The ICE client requests an Allocation of a relay, and after successful authentication the TURN server provides a RELAYED-ADDRESS containing the transport address allocated on that server for the client.
These types of ICE candidates have different priorities, 'host' being at highest priority and 'relay' at lowest priority; this is a way to privilege direct interconnection when possible (but that not necessarily represents the best solution in terms of connection quality and in general of Quality Of Experience).
This diagrams shows a typical process where ICE candidates are gathered and sent to the other party:
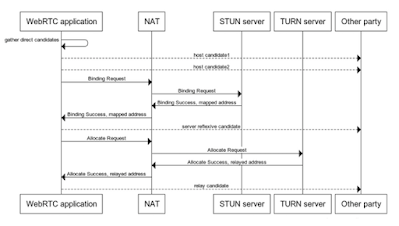
In this example the candidates are communicated as soon as they are retrieved. This technique is called Trickle ICE and was designed to ensure that the connectivity checks can happen as soon as the candidates are available.
Without Trickle ICE, the WebRTC client would need to wait for all the candidates to be collected before sending an offer or an answer, increasing the session set up time.
The candidates are transmitted over a signalling system established between the two parties. This is outside of the WebRTC specifications and application-specific.
The WebRTC client will then receive the ICE candidates from the other party, and it will build a list of “candidate pairs”: each local candidate will be paired with each remote candidate.
After this operation the connectivity checks can begin.
Let’s see it with an example, assuming UDP as transport for all cases. The WebRTC client has a local host candidate, IP1:port1, and has received a remote host candidate, IP2:port2. It builds a “candidate pair” with the two: {IP1:port1, IP2:port2}.
The WebRTC client will start sending STUN Binding Requests with source IP1:port1 and destination IP2:port2. These requests use STUN short-term authentication, and contain a username and password that were previously exchanged when transmitting the candidates inside the SDP offer/answer.
If the Binding Request reaches the other party on IP2:port2, then the other party will authenticate the request, and respond with a Binding Success Response, including the MAPPED-ADDRESS attribute, containing the source of the request.
If the Binding Success Response reaches the WebRTC client, then it will identify the request by looking into the transaction ID and mark the check as Successful, and so suitable for exchanging media.
If for any reason the Binding Success Response is not received, then the candidate pair will remain in a In Progress state for some time, and then move to Failed: that pair cannot be used to exchange media.

It’s important to note that this is symmetrical: the other party too can start the connectivity check from IP2:port2 towards IP1:port1. To avoid a conflict, the parties assume the role of "controlling" or "controlled" agent. The controlling agent will be the one deciding which candidate pair will be used for exchanging media.
Before media can flow through a TURN server, a client must create a Permission. This is important during ICE connectivity checks.
For ICE candidates of type 'relay', the connectivity check will be performed sending Binding Requests that traverse the TURN server and reach the other party on the relay side. The Binding Requests will be carried by a Send Indication, destined to the remote candidate as peer address. The TURN server will only accept it and relay it to the destination if a Permission has been granted for that peer.

(NAT has been omitted in this diagram for simplicity)
Of course a TURN allocation must exist for the CreatePermission request to succeed, but that’s already been created during the candidate gathering phase.
If the candidate pair selected for exchanging media will be one with a local 'relay' candidate, then typically the WebRTC client binds a TURN Channel to the other party, and starts exchanging media using ChannelData messages, instead of Send/Data Indications.
There are more details that can be discussed, like managing timeouts, role conflicts, ICE Lite, etc, which we will address in other articles. One additional aspect is important here: we mentioned three types of candidates, host, server reflexive and relayed, but there’s a fourth one, "peer reflexive".
Peer reflexive candidates are not provided directly by a party during candidate exchange, but are instead discovered dynamically during the connectivity checks. Getting back to the previous example with a candidate pair {IP1:port1, IP2:port2}, depending on NAT conditions, the response to the Bind Request from IP1:port1 can be received by another source, IP3:port3.
The WebRTC client can verify IP3:port3 is sending a valid response by checking the transaction ID, and if successful it will dynamically add a remote candidate of type peer reflexive. Sometimes the peer reflexive candidate is the only one suitable and will be used to exchange media.
Chrome’s chrome://webrtc-internals, Firefox’s about:webrtc and Safari's "WebRTC Logging" will show the list of candidates and the pair that was selected, so those tools are of great value when troubleshooting.
If you take a trace on the computer running the WebRTC client, you’ll be able to see the STUN Binding Requests and Responses, and CreatePermission, Send/Data Indications for connectivity checks if unencrypted TURN is used. Wireshark will filter those messages for you if you use the ‘stun’ filter, and will also be able to interpret the Binding Request/Response carried inside Send/Data Indications (and also the RTP streams, but that’s for another article).
If you're interested about troubleshooting TURN sessions, take a look at this other article, "Troubleshooting TURN".